Acceptance tests are formal tests that verify if a system satisfies business requirements. In an optimization context, an acceptance test determines if business goals or key performance indicators (KPIs) are met by a new model (typically on a set of inputs always used for testing) and allow you to determine whether or not to deploy a model update to production.
When an acceptance test is run, data is collected from runs made with the baseline and candidate instances, and then the candidate instance's metrics are compared to the baseline instance’s metrics. The result of these comparisons is determined by the operator for how the metric should be evaluated. For example, if should increase is set for a metric, it means that the value of the metric in the output returned for the candidate instance should be greater than the same metric value returned from the baseline instance.
To be concise, an acceptance test is based on a batch experiment. For the metrics specified in the acceptance test, it compares the results of two instances: candidate vs baseline. For each metric (comparison), the acceptance test gives a pass/fail result based on the operator. An acceptance test can be thought of a view on a batch experiment, with a focus on the metrics.
The ID and name of the acceptance test and the underlying batch experiment must be the same.
When using subscription apps, make sure the candidate and baseline instances do not use a major version, i.e.: v1 or v2. Instead, assign a complete (specific) version to your instances, i.e.: v1.1.0.
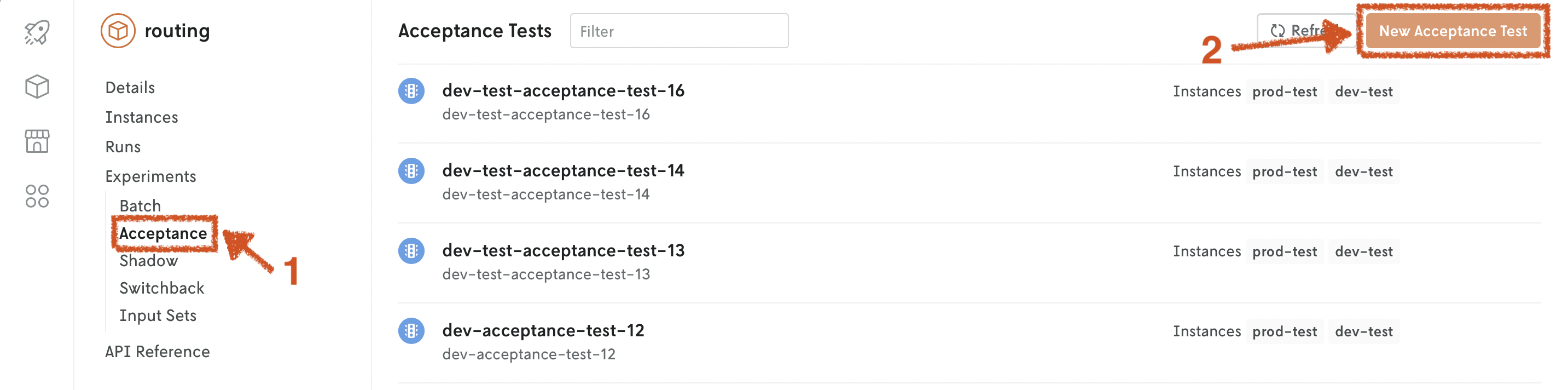
Acceptance tests are designed to be visualized in the Console web interface. Go to the app, Experiments > Acceptance tab.
There are several interfaces for creating batch experiments:
- Console: use the web interface.
- Nextmv CLI: use your terminal.
- Python SDK: use Python.
- Cloud API: use the HTTP endpoints.
Defining metrics
When you are creating an acceptance test you must define the metrics you want to analyze. At least one metric is required to run an acceptance test. These metrics are user-defined, though if you are using a subscription app or a custom app based on a template, there are some pre-defined metrics available to you.
The metrics are governed by the statistics convention. Any item under the statistics block is a valid entry for an acceptance test metric. To specify a metric, use object dot notation for path reference, starting from the .statistics field of the output. The metric is specified relative to the parent statistics block.
To compare metrics, you must define the operator for the comparison.
| Operator | Symbol | Description |
|---|---|---|
eq | == | Equal to |
gt | > | Greater than |
ge | >= | Greater than or equal to |
lt | < | Less than |
le | <= | Less than or equal to |
ne | != | Not equal to |
Consider the meal allocation output as an example.
These are valid metrics for the acceptance test:
result.valuewithle: the value of the result in the candidate must be less than or equal to the baseline.result.custom.constraintswitheq: the number of constraints in the candidate must be equal to the baseline.result.custom.variableswitheq: the number of variables in the candidate must be equal to the baseline.run.durationwithge: the run duration of the candidate must be greter than or equal to the baseline.
Console
Go to the Console web interface, and open your app. Go to the Experiments > Acceptance tab. Click on New Acceptance Test. Fill in the fields.
A new batch experiment will be created with the same ID and name as the acceptance test.
To specify many metrics, it is recommended that you use the Free-form tab in the Metrics section. In this view, each metric is specified as a new line in this format:
path: operator
For example:
Nextmv CLI
Define the desired acceptance test ID and name. As mentioned above, an acceptance test is based on a batch experiment.
- If you already started a batch experiment, you don't need to provide the
-s, --input-set-idflag. In that case, the ID and name of the acceptance test and the underlying batch experiment must be the same. - If you didn't start a batch experiment, you need to provide the
-s, --input-set-idflag and a new batch experiment will be created for you, with the same ID and name as the acceptance test.
Start by defining the metrics you want the acceptance test to use.
The command will produce a metrics.json file. Edit this file to include the metrics you want to use.
Once the metrics.json file is ready, run the following command to create the acceptance test.
Cloud API
Define the desired acceptance test ID and name. As mentioned above, an acceptance test is based on a batch experiment. The acceptance test ID and name must be the same as the batch experiment ID and name, respectively.
Create and start acceptance test.
Create an acceptance test. The test relies on a batch experiment, so a batch experiment must already exist.
You can get the information of an acceptance test or list the information for all acceptance tests in an app using the following endpoints:
Get acceptance test information.
Get the information of an acceptance test.
List all the existing acceptance tests.
List acceptance tests.
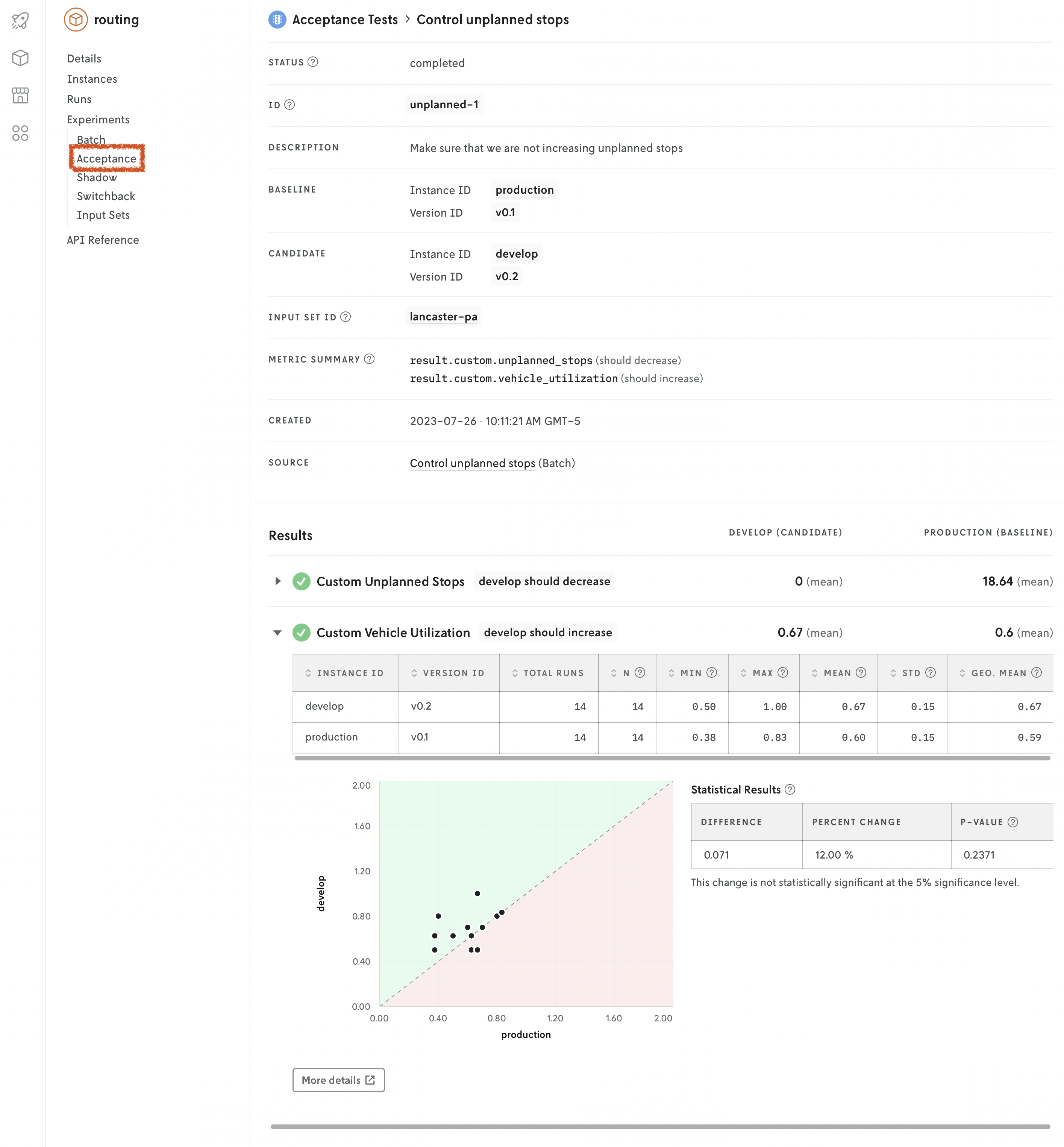
Results
Also included is a Statistical Results table that can be used as an aid when interpreting the significance of the results. It includes the difference between the mean value of the metric for the candidate and the baseline instance, the percentage change of that difference, and the associated p-value.
The p-value is calculated with the Wilcoxon signed rank test with continuity correction. This value gives an indication of whether the change in value is statistically significant, but does not account for the intended direction of the test. If there is no difference in the data, the p-value is not provided.
Note that in cases where one of the runs from either the candidate or baseline instances failed, the paired observation for this input will be excluded from analysis.
Delete an acceptance test
Deleting an acceptance test will also delete all of the associated information. Note that deleting it will not delete the underlying batch experiment and its runs.
This action is permanent and cannot be undone.
To delete an acceptance test, you can use the following interfaces:
Console: use the web interface. Use the
Deletebutton in the acceptance test details.Nextmv CLI: use your terminal.
The command will prompt you to confirm the deletion. Use the
--confirmflag to skip the confirmation.Cloud API: use this HTTP endpoint.
DELETEhttps://api.cloud.nextmv.io/v1/applications/{application_id}/experiments/acceptance/{acceptance_id}Delete acceptance test.
Delete an acceptance test.
You will not be prompted to confirm the deletion.